
用户级线程
进程切换与线程切换的联系
进程切换——> 资源 (内存)+ 指令执行序列
线程切换——>保留了并发的优点同时又避免了进程切换的代价(实质上就是映射表不变而PC指针变)
每个进程都包含一个映射表,如果进程切换了,那么程序选择的映射表也要跟着换。进程的切换主要包含两个部分即指令的切换 + 映射表的切换。其中指令的切换就是从这段程序跳到另外一段程序去执行,映射表的切换就是内存资源的切换。而线程的切换同属于一个进程里,不存在映射表的切换,只是指令的切换。所以在了解进程的切换之前,我们先来了解线程的切换,进程的切换就是在线程切换的基础上加上映射表的切换。
多线程实现浏览器网页的加载
为什么 通常在网速比较慢的时候我们访问一个网站时,网页的加载过程通常是先出现一些文本,过了一会再出现图片、视频呢?
因为浏览器向服务器发起访问的程序是一个进程,它包含多个线程,如:用来从服务器接收数据的线程、显示文本的线程、用来处理图片的线程以及用来显示图片的线程。设想一下,如果这些线程变成一个程序顺序执行会怎么样?
如果依次执行,那么通常向服务器接收数据的线程会比较慢,只有在当前线程执行完毕才开始渲染显示,那么将有一段时间网页是空的,影响用户体验。那么网页的加载是如何实现的呢?
多线程并发交替执行,当接收数据线程接收完文本数据后就切换到显示文本线程加载文本信息,之后再切换回去接收图片等数据再加载,交替执行。那么为什么加载网页的是多个线程的协同而不是多个进程呢?
浏览器接收服务器的数据肯定都是存储在一个缓冲区中的,并且缓冲区是线程共享的。如果是多进程实现的话,那就必然会有多个映射表,接收数据的进程需要把数据写到自己的缓冲区上,而显示处理进程又需要从该缓冲区中拿到数据,因为地址是分离的,取数据时就会有数据拷贝的问题,特别麻烦。因为这些程序本身就涉及合作需要共享数据,所以就没有必要进行地址分离,完全可以在一块地址上进行。因此通过多线程实现就是最好的选择。
用户级线程切换的实现
Yield——> 核心切换
Create——> 创造出第一次切换的样子
要实现线程的切换我们首先需要创建两个线程
线程1
1 | 100:A() |
1 | void Yield1() |
线程2
1 | 300:C() |
1 | void Yield2() |
两个执行序列与一个栈 实现两个线程的切换
首先线程1中A()执行,然后跳到B()执行 ,并将函数返回地址104压栈。进入到B()之后将调用Yield1(),并将返回地址压栈,执行Yield1()函数将会跳到300处到线程2去执行,然后在C()函数中执行D()函数并将304压栈,跳到D()函数去执行。接着执行Yield2(),并将404压栈。此时栈中元素如下:
1 | 104,204,304,404 <(栈顶) |
此时执行Yield2()函数,将跳到204,回到线程1处去执行。现在看似实现了两个线程的切换,但是继续执行将出大问题了?
因为当跳回线程1中204的位置来执行。紧接着遇到了就是B()函数的 },此处的 } 将会编译成一段汇编指令 ret 执行弹栈的操作。此时栈顶元素为404,执行弹栈操作后将会跳到404处即线程2去执行,所以问题就出现了。本来B()函数返回要回到当前线程的104处去执行,但是反而跑去线程2去执行了。为什么呢?? ——> 两个线程共用了一个栈就是原罪,所以要想解决这个问题就要把一个栈变成两个栈,让两个线程在各自的栈中玩自己的就好了啊。这也是为什么一个进程中的多个线程要有自己私有的栈了~
从一个栈到两个栈
当从一个栈到两个栈转换后,执行以上操作此时栈中元素情况如下:
线程1的栈
1 | 104,204 <(栈顶) |
TCB1
1 | esp = 1000 |
线程2的栈
1 | 304, 404 <(栈顶) |
TCB2
1 | esp = 2000 |
此时每个线程各用一套栈,那么要想实现线程的切换就要考虑两套栈的切换。两套栈的切换这种动态的过程就需要记录存储当前状态的信息,即栈的信息要存放起来保证日后切回来的时候能找得到,这就需要一个数据结构来存储两套栈的地址信息了,此时线程控制块TCB出现了,TCB是一个全局的数据结构,专门用来记录两套栈的信息。 esp是物理寄存器,在CPU中,esp指向的即是当前栈的地址,把栈切换实质上就是esp寄存器的改变。
因为涉及到esp的改变所以我们要重写Yield()函数,我们主要分析下Yiele2()函数,重写后的Yield2()函数如下:
1 | void Yield2() |
当前esp指向2000即线程2的栈顶元素地址,要想改变esp,首先要将2000保存在 TCB2中,然后将1000赋给esp,(1000为之前线程1跳到线程2时所保存在TCB1中的地址信息)。此时栈就已经切换回到线程1了。栈切换后接着就是PC的切换,PC切换后就要跳到204去执行。跳到204去执行紧接着就又会遇到B()函数的返回 },此时又将执行弹栈操作,当前esp->1000 栈顶元素为204,所以弹栈204,并再次跳到204去执行(每次弹栈就要跳去执行)。那么问题又出现了,我们不是刚刚从线程2切换回线程1执行完B()函数并返回嘛??B()函数执行完应该回到104处去执行啊?,怎么又要跳回204重新执行一遍呢??
因为在Yield2()这个函数中 jump 204是跳到204去执行,那么Yield2()函数就无法执行到 },所以也就无法将204弹栈,因此导致204处多次执行。那么我们怎么办呢?? ——> 再次修改Yield2()函数
1 | void Yield2() |
当前Yield2()函数如上,删去了jump204; 仅仅保留了 栈的esp指针的切换。此时执行完Yield2()函数即执行完 }后,将执行弹栈操作,而此时栈已经切换回TCB1,栈顶元素正好是204,那就直接跳到204处去执行,204处执行完后,B()函数返回 }, 接着弹栈 104 再跳回 A() 函数中去执行。一切都变得完美了!!
通过上面的分析我们发现,两个线程的样子即为1.两个栈、2.两个TCB、3.切换的PC在栈中。 TCB和栈相互配合即为线程切换的核心。 实现TreadCreate 的核心就是用程序做出这三样东西。
1 | void TreadCreate(A) |
至此我们便可以通过 ThreadCreate 与 Yield 两个函数的配合实现用户级线程的切换了!
用户级线程的缺点
用户级线程是在用户态中切来切去,一般并不需要进入到内核,操作系统就感知不到其存在。当需要管理硬件的时候就要进入到内核,一旦遇到IO后操作系统CPU就会切换,因为操作系统感知不到用户级线程的存在也就不会将CPU执行权重新交回到当前进程去执行,而是去执行其他的进程,那么当前进程就要等待,对于一些实时性比较强的应用,用户体验会很差。这也是Chrom浏览器打开新标签采用多进程的原因
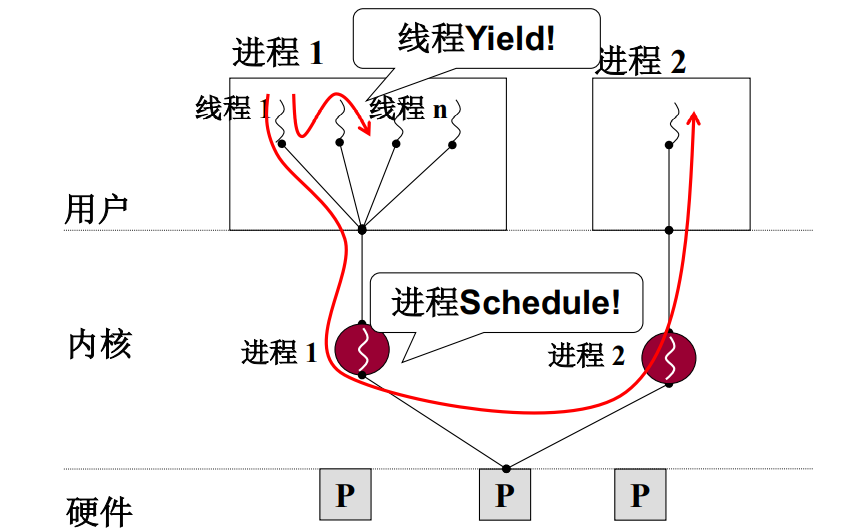
核心级线程
多处理器和多核的区别
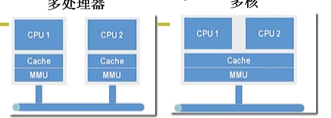
多处理器:每一个CPU有自己的一套映射即MMU(MMU-> 内存映射)
多核:多个CPU共用一套MMU => 并行 -> 类似于线程
一个系统中往往是用户级线程和核心级线程同时存在的
一个系统如果不实现核心级线程,那多核实质上是没有用的,多核是建立在核心级线程的基础上的
从两个栈到两套栈
核心级线程既能在用户态中跑,又能在内核态中跑,那就意味着要进入到内核。先前我们了解到用户级线程需要用户栈来记录函数的调用信息,那核心级线程在用户态执行的时候需要用户栈去记录用户态的函数调用,到内核中执行时必然也会进行系统函数调用,那自然也需要一个内核栈来记录其在核心态中执行的函数调用信息。所以核心级线程就需要一套栈,相应的线程切换就会从两个栈变成两套栈。 同样此前用户级线程中一个TCB关联一个栈,TCB的切换引起两个用户栈的切换,而现在核心级线程中一个TCB就应该关联一套栈,并且TCB在内核中,在内核中切换TCB就会切换两套栈。
用户栈与内核栈的关联
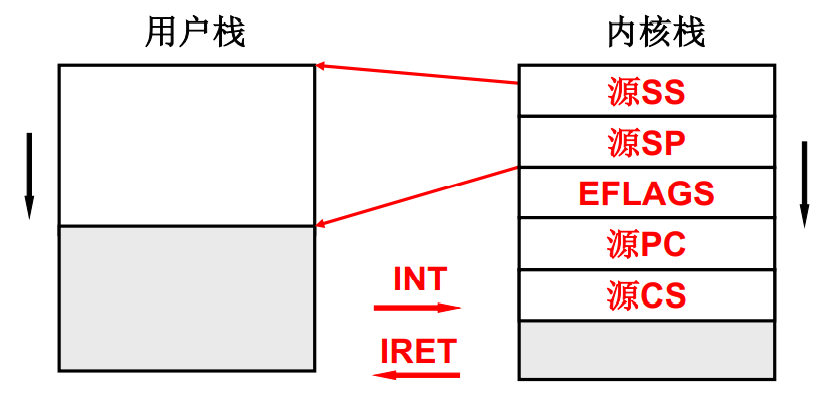
起先是在用户态中执行,就会在用户栈中来回折腾,一旦有了中断(INT、鼠标、键盘、时钟中断)就会到内核态并启用内核栈(intel 硬件做好了的)。即每个用户栈关联一个内核栈,起先在用户栈执行的时候就用用户栈,一旦经过系统中断进入内核态,操作系统便会通过硬件寄存器找到这个线程所对应的内核栈并启用内核栈。
启用内核栈后,首先就会压入源SS和源SP (在用户态执行的栈),同时压入源PC、源CS (在用户态执行的指令-> 执行到哪里了-> 方便跳回来后继续执行)。
通过将用户栈的信息压栈就实现了用户栈与内核栈的相关联-> 相当于从内核态向上拉了一条连接到用户态的链。
同样当在内核栈中执行完需要返回到用户栈的时候便通过 IRET(中断)指令执行弹栈操作,根据栈底压入的用户栈信息就又返回到用户栈去执行了。
实例解析核心级线程的切换
1 | 100:A() |
首先A()函数调用B()函数将104压栈,执行B()函数并在B()函数中调用read()函数,read()是一个库函数,所以就会展开成一 段包含int 0x80的中断代码,此时该核心级线程从用户态跳到内核态去执行,同时用户栈将204压栈,并根据硬件寄存器启用对应的内核栈。
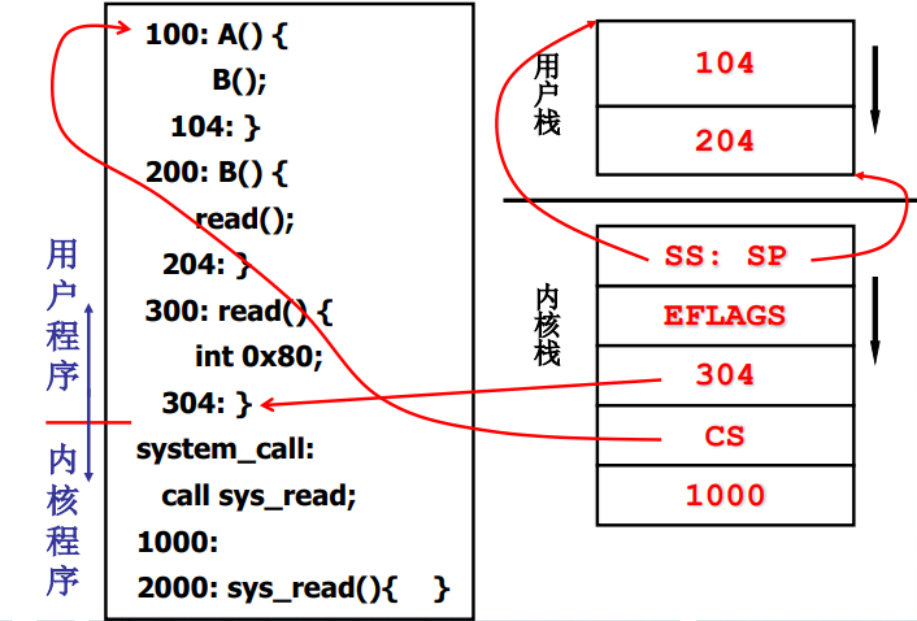
此时用户栈信息如下:
1 | 104, 204 < (栈顶) |
int指令执行完毕紧接着将304压入内核栈,并将CS(段基址)压入栈,接着跳到system_call去执行,在system_call中查表调用系统函数sys_read(),同时将1000压栈。 此时内核栈信息如下:
1 | SS : SP , EFLAGS , 304 , CS , 1000 <(栈顶) |
1 | sys_read(){ |
此时已经进入内核并执行系统函数 sys_read(),一旦执行sys_read()便会启动磁盘读,启动磁盘读自己就变成阻塞了,一阻塞就会让出CPU执行权引起调度。紧接着操作系统就会switch_to(cur,next)找到下一个线程并跳去执行。其中 - > cur : 当前线程的TCB next : 下一个线程的TCB (TCB中存储的即为各自内核栈的esp)
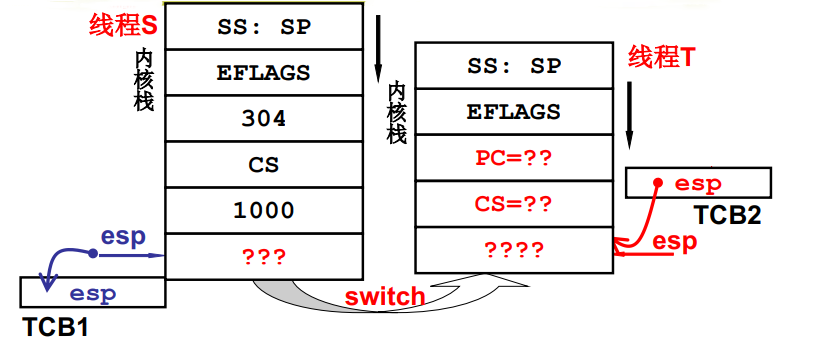
如上图所示,我们根据TCB中的esp 切换TCB,此时便从线程S跳到线程T去执行了,紧接着执行的就是线程T的内核态代码,我们知道一个线程在执行的过程中一般绝大部分时间是在用户态执行的,只有当调用系统接口的时候才会进入到内核中去执行,溜达一圈之后会继续回到用户态去执行。所以此时线程T在内核态执行完后一定会回到用户态去执行。那么它如何返回到用户态去执行呢?
iret中断返回 –> 上图 线程T 的 “????” 处即为一段包含 iret的代码,根据中断返回->弹栈操作将线程T用户态的执行指令信息以及用户栈信息弹出并跳到用户态去执行即可!!!
内核级线程切换核心思想—switch_to五段论
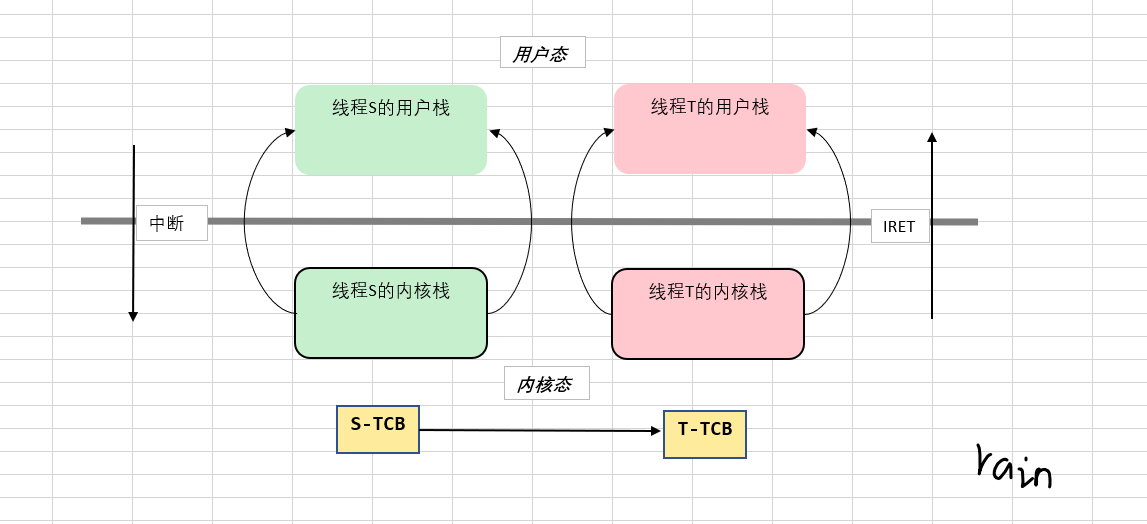
switch_to(cur, next)五段论
- 首先要通过中断进入到内核;
- 当需要切换时就要找到相应的TCB;
- 完成TCB的切换;
- 当TCB切换完之后就要 根据TCB完成内核栈的切换;
- 内核栈切换完毕之后在通过
IRET中断返回指令将相应的用户栈切回来;
首先是线程S在用户态中执行,一旦经过系统中断便进入到内核态去执行,就会用内核栈,同时内核栈又与TCB相关联。一旦需要切换,就会根据线程S的TCB找到下一个线程的TCB即线程T的TCB,所以就完成了TCB的切换。而线程T的TCB对应有线程T的内核栈,也就同样可以根据TCB完成内核栈的切换。线程T的内核栈又关联着线程T的用户栈,就可以根据IRET中断返回指令切回到用户态去执行。以上便是核心级线程切换的思路!!
用户级线程VS核心级线程
| TYPE | 用户级线程 | 核心级线程 | 用户+核心级线程 |
|---|---|---|---|
| 利用多核 | 差 | 好 | 好 |
| 并发度 | 低 | 高 | 高 |
| 代价 | 小 | 大 | 中 |
| 内核改动 | 无 | 大 | 大 |
| 用户灵活性 | 大 | 小 | 大 |
参考资料