
什么是CPU调度?
调度即为切换-> 获取到 switch_to(cur, next) 中的 next,一旦获得到next 便切换到 next;
如下图所示:PID1的进程正在执行,当执行到一定程度后由于阻塞或者时间片到时等原因,不让它继续执行了。现在操作系统需要切换另外一个进程去执行,但是现在就绪队列中有两个进程分别为PID2、PID3。PID2是先前read() 引发磁盘读阻塞现在又处于就绪了,PID3是先前时间片到时而阻塞现在又就绪了,那么此是PID2、PID3都处于就绪状态,CPU接下来该切换到PID2好呢还是切换到PID3好呢??
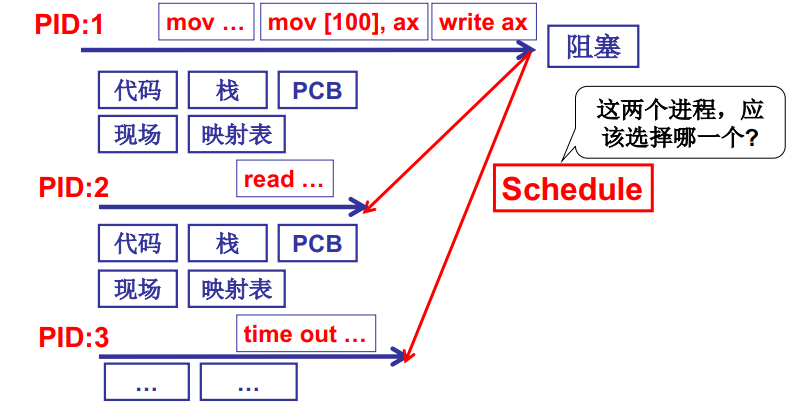
CPU调度的直观想法
FIFO
先入先出,根据就绪队列的先后顺序执行。
类似于银行排队办理业务,结合生活我们可以发现如果一个人仅仅是简单的询问并不办理手续那他也要跟着后面排队嘛??显然这种策略是不合理的!
Priority
优先级 –> 给每个进程都设置优先级,根据优先级来选取下一个执行的进程。对于一些时间短的任务可以适当增加它的优先级 ,先让它执行。但是你怎么知道这个任务将来会执行多长时间呢?–> 如果上面那个人询问的越来越长,那怎么办呢?同样难道就因为我的执行任务很长就把我一直排在后面,这也不合适吧 !
面对诸多场景如果设计调度算法呢?
如何让进程满意?-> 时间复杂度
- 尽快结束任务:周转时间短(从任务进入到任务结束)
- 用户操作尽快响应:响应时间短(从操作发生到响应)
- 系统内耗时间少:吞吐量大(完成的任务量)
总原则:系统专注于任务执行,又能合理调配任务;
如何做到合理呢?
操作系统做CPU调度的时关键在于折中和综合
通常一个系统中往往既有前台任务又有后台任务,并且前台任务和后台任务的关注点不同 -> 前台任务关注响应时间,后台任务关注周转时间然而吞吐量和响应时间之间存在矛盾
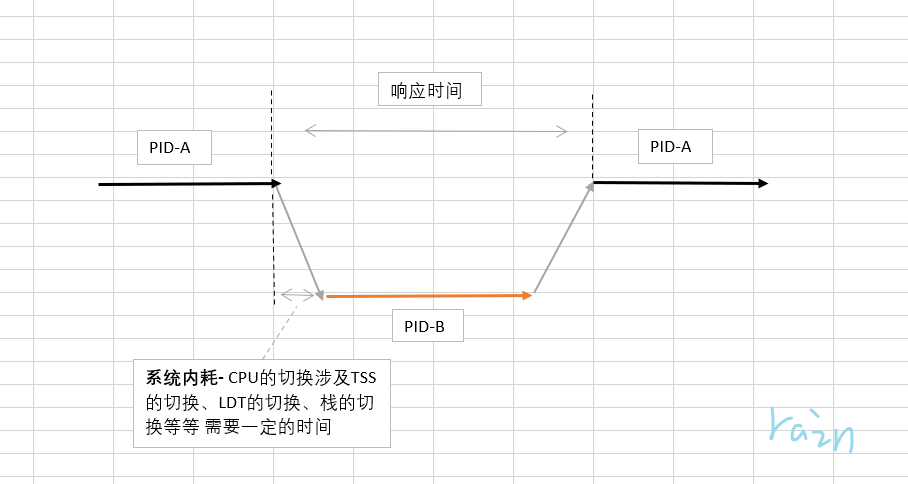
响应时间小 -> 切换次数多 -> 系统内耗大 -> 吞吐量小
即如果想保证用户的体验,前台的响应时间就要短,那就需要频繁的切换,因为CPU的切换是需要时间的,频繁的切换会造成大量的系统内耗。想一想如果CPU的工作都花在切换上了,正经活不干了,那吞吐量自然就小了,后台的周转时间自然会受到影响。
IO约束型和CPU约束性任务有各自的特点
- IO约束型即CPU执行区间短的切换的频率特别大,比如银行的出纳、word文档总是需要写入磁盘,等待键盘的输入,典型的IO约束型。
- CPU约束型即很长一段时间没有IO,CPU的执行区间很长,一顿在完成计算,比如Matlab计算矩阵的时是典型的CPU约束型任务。
因为它们都有各自的特点,那么在折中和综合后的优先级设置中,IO约束型任务的优先级往往要高一些。因为IO约束型任务优先级高的话就会先执行,它稍微执行一段之后IO就启动了,然后就紧接着切出去执行CPU约束型任务,现在IO和CPU就并行起来了,两种任务就都能很高效地执行。而如果是CPU约束型任务优先级很高的话,那它先执行,CPU就会一直执行很少给IO约束型任务调度的机会,那么IO约束型进程就会饥饿。通过分析我们发现IO约束型任务往往是前台任务,和用户的交互很多,CPU约束型任务往往是后台任务。
所以折中和综合让操作系统的调度变得异常的复杂……
常用的CPU调度算法
FCFS-> First Come, First Served
先来先服务
SJF:短作业优先
如何将完成所需时间小的任务提前,那么它的周转时间就会缩短,平均周转时间也就减少。系统的平均满意度提高。但是这样所需时间长的任务总是被排在后面,导致响应时间又很长??
HRRN : 最高响应比优先法
最高响应比优先法(HRRN,Highest Response Ratio Next)是对FCFS方式和SJF方式的一种综合平衡。FCFS方式只考虑每个作业的等待时间而未考虑执行时间的长短,而SJF方式只考虑执行时间而未考虑等待时间的长短。因此,这两种调度算法在某些极端情况下会带来某些不便。HRN调度策略同时考虑每个作业的等待时间长短和估计需要的执行时间长短,从中选出响应比最高的作业投入执行。这样,即使是长作业,随着它等待时间的增加,W / T也就随着增加,也就有机会获得调度执行。这种算法是介于FCFS和SJF之间的一种折中算法。
算法原理:响应比R定义如下: R =(W+T)/T = 1+W/T
其中T为该作业估计需要的执行时间,W为作业在后备状态队列中的等待时间。每当要进行作业调度时,系统计算每个作业的响应比,选择其中R最大者投入执行。
- 算法优点:由于长作业也有机会投入运行,在同一时间内处理的作业数显然要少于SJF法,从而采用HRRN方式时其吞吐量将小于采用SJF 法时的吞吐量。
- 算法缺点:由于每次调度前要计算响应比,系统开销也要相应增加。
RR: 按照时间片来轮转调度
按照时间片可以很好的满足响应时间,但是时间片的设置需要好好考虑
时间片太大 -> 响应时间太长; 时间片小 -> 切换频繁内耗大,吞吐量小;
折衷:进程的个数要有所限制 ;时间片10 ~ 100ms,切换时间0.1~1ms(1%)
一些问题的思考
SJF解决了周转时间,RR解决了响应时间,但是如果响应时间和周转时间同时存在呢?就比如word很关心响应时间,而gcc很关心周转时间,这两类任务同时存在怎么办呢?
直观想法:定义前台任务和后台任务两个队列,因为前台任务更看重响应时间,所以使用RR,后台任务更看重周转时间,采用SJF。它们之间使用优先级调度 -> 只有当前台任务没有的时候才调度后台任务

那么问题就又出现了,如果前后台任务切换是绝对的优先级调度,如果前台任务总是不停的出现,那么前台任务就总是先执行,那很可能后台的任务永远也得不到执行,就会造成后台进程饥饿。这显然又不合理了,那该怎么解决呢??
优先级动态的调整–> 后台任务优先级动态的升高
但是后台任务优先级提升上来之后,因为后台任务往往是CPU约束型任务又采用的SJF策略,一旦执行就很难再停下来去执行前台任务,前台任务的响应时间就又没法得到保证了??啊这……
为了保证前台任务,后台任务也不能让它一直执行,后台任务你可以上来,但你执行完一段时间优先级应该再下去,释放CPU执行权,所以后台任务也要有时间片。但是如果前后台任务都是单纯的只有时间片就又退化成了RR,也就又没有了优先级的概念???
所以既要以轮转调度RR为核心,又要在轮转调度的基础增加一些优先级。
除此之外还有很多其他的问题,比如:
- 我们怎么知道哪些是前台任务,哪些是后台任务,fork时告诉我们吗?
- gcc就一点不需要交互吗? Ctrl+C按键怎么工作?
- word就不会执行一段批处理吗? Ctrl+F按键?
- SJF中的短作业优先如何体现? 如何判断作业的长度?
所以我们需要设计一个调度算法,这个调度算法要有一定的学习能力,它能识别不同的任务,并且可以根据任务的变化自身作出调整,同时这个算法还要尽可能的简单,既要考虑前台任务又要考虑后台任务。从而达到操纵系统对整体任务的折中以及综合。
Linux 0.11 的调度函数schedule()
1 | //在kernel/sched.c中 |
在Linux中,将PCB做成了一个数组,NR_TASKS就是数组的范围。首先将p指向PCB的最后一个元素,然后遍历整个就绪队列找到counter最大的进程,如果counter > 0则直接跳出循环执行 switch_to(next),跳到next进程去执行。如果counter <= 0 则更新所有进程的优先级;
counter的两个作用
优先级
1 | while(--i) |
通过分析我们发现,此时的counter类似于优先级的概念,即我们从就绪队列中找到一个优先级最大的进程并跳去执行。
如果当循环遍历结束找到的counter 不大于零 –>说明就绪队列中进程的时间片用光了。此时重置一下所有进程(就绪队列 + 阻塞队列) 的counter。
1 | for(p=&LAST_TASK;p>&FIRST_TASK;--p) |
此时各个进程的counter = counter(当前) / 2 + priority(初始);当进程一直阻塞,其counter = 1+1/2 +1/4 + 1/8 …最后会收敛于2*p
我们知道先前经过IO阻塞的进程的counter一定要比经过就绪队列执行后的进程的counter要大,所以当重置后,其counter也一定更大,那么当IO阻塞型的进程再次回到就绪队列后,其优先级一定更高,就会优先执行,所以在一定程度上就照顾了IO型任务。
时间片
counter又是典型的时间片,所以是轮转调度,保证了响应
1 | void do_timer(...) //在kernel/sched.c中 |
如果当前进程的counter大于0,就减1并且结束函数。如果小于等于0,就将当前进程的counter置为0,执行schedule函数。
总结
- 通过counter实现了优先级动态的调整,同时保证了响应时间的界;
- 经过IO后,counter就会变大;IO时间越长,counter越大,照顾了IO进程,变相的照顾了前台任务;
- 后台进程一直按照counter轮转,近似于SJF调度;
- 每个进程只用维护一个变量counter,简单、高效,简直完美!
参考资料